RLLTE Hub: Large-Scale and Comprehensive Data Hub for RL
Support list
| Benchmark | Algorithm | Remark | Reference |
|---|---|---|---|
| Atari Games | PPO | 10M, 💯📊🤖 | Paper |
| DeepMind Control (Pixel) | DrQ-v2 | 1M, 💯📊🤖 | Paper |
| DeepMind Control (State) | SAC | 10M for Humanoid, 2M else, 💯📊🤖 | |
| DDPG | 🐌 | ||
| Procgen Games | PPO | 25M, 💯📊🤖 | Paper |
| DAAC | 🐌 | Paper | |
| MiniGrid Games | 🐌 | 🐌 | 🐌 |
Tip
- 🐌: Incoming.
- (25M): 25 million training steps.
- 💯Scores: Available final scores.
- 📊Curves: Available training curves.
- 🤖Models: Available trained models.
Trained RL Models
The following example illustrates how to download an PPO agent trained the Atari benchmark:
from rllte.hub import Atari
agent = Atari().load_models(agent='ppo',
env_id='BeamRider-v5',
seed=0,
device='cuda')
print(agent)
Use the trained agent to play the game:
from rllte.env import make_envpool_atari_env
from rllte.common.utils import get_episode_statistics
import numpy as np
envs = make_envpool_atari_env(env_id="BeamRider-v5",
num_envs=1,
seed=0,
device="cuda",
asynchronous=False)
obs, infos = envs.reset(seed=0)
episode_rewards, episode_steps = list(), list()
while len(episode_rewards) < 10:
# The agent outputs logits of the action distribution
actions = th.softmax(agent(obs), dim=1).argmax(dim=1)
obs, rewards, terminateds, truncateds, infos = envs.step(actions)
eps_r, eps_l = get_episode_statistics(infos)
episode_rewards.extend(eps_r)
episode_steps.extend(eps_l)
print(f"mean episode reward: {np.mean(episode_rewards)}")
print(f"mean episode length: {np.mean(episode_steps)}")
# Output:
# mean episode reward: 3249.8
# mean episode length: 3401.1
RL Training Logs
Download training logs of various RL algorithms on well-recognized benchmarks for academic research.
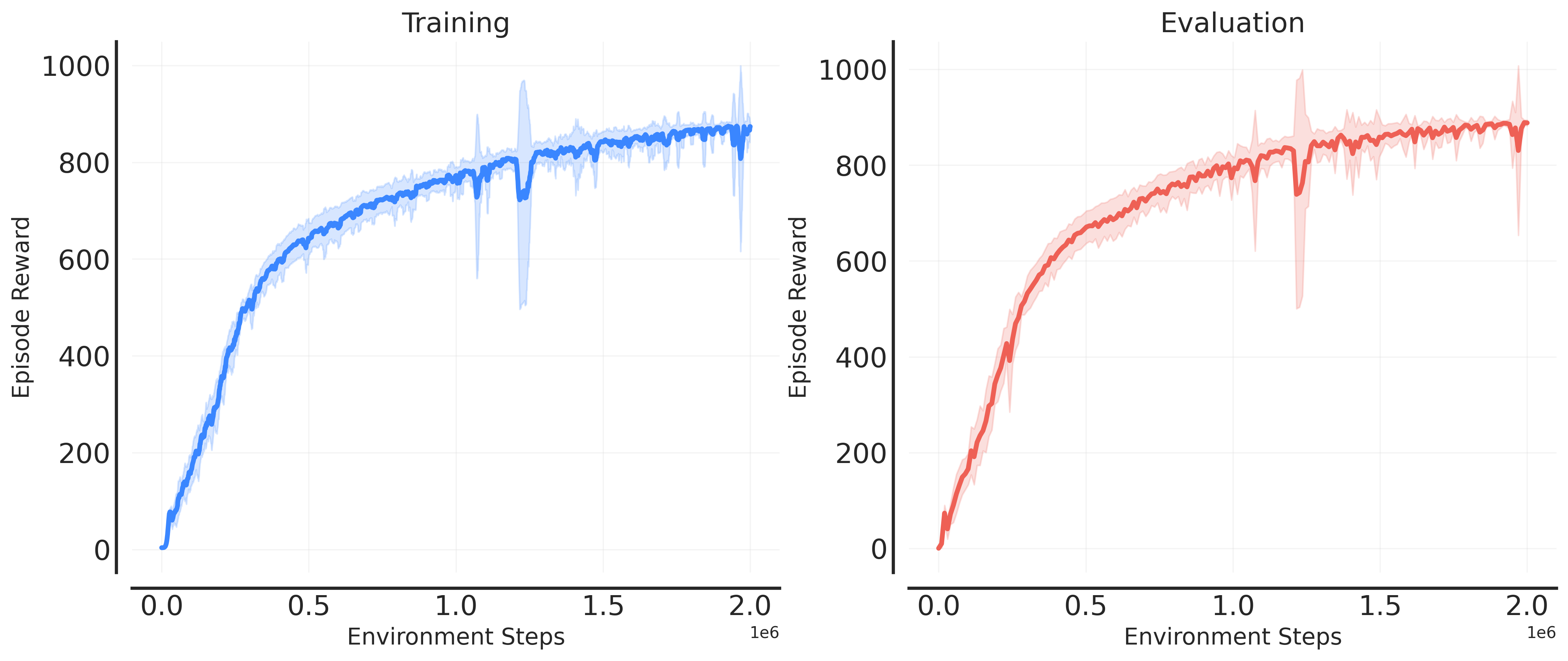
Training Curves
The following example illustrates how to download training curves of the SAC agent on the DeepMind Control Suite benchmark:
Dict of NumPy array like:
curves
├── train: np.ndarray(shape=(N_SEEDS, N_POINTS))
└── eval: np.ndarray(shape=(N_SEEDS, N_POINTS))
Visualize the training curves:
Test Scores
Similarly, download the final test scores via
This will return a data array with shape(N_SEEDS, N_POINTS).
RL Training Applications
Developers can also train RL agents on well-recognized benchmarks rapidly using simple interfaces. Suppose we want to train an PPO agent on Procgen benchmark, it suffices to write a train.py like:
from rllte.hub import Procgen
app = Procgen().load_apis(agent="PPO", env_id="coinrun", seed=1, device="cuda")
app.train(num_train_steps=2.5e+7)
.load_apis(), and all the hyper-parameters can be found in the reference of the support list.