Contents
概述
受通信领域长期演进(LTE)标准项目的启发,RLLTE旨在提供用于推进RL研究和应用的开发组件和工程标准。除了提供一流的算法实现外,RLLTE还能够充当开发算法的工具包。

RLLTE简介.
RLLTE项目特色: - 🧬 长期演进以提供最新的强化学习算法与技巧; - 🏞️ 丰富完备的项目生态,支持任务设计、模型训练、模型评估以及模型部署 (TensorRT, CANN, ...); - 🧱 高度模块化的设计以实现RL算法的完全解耦; - 🚀 优化的工作流用于硬件加速; - ⚙️ 支持自定义环境和模块; - 🖥️ 支持包括GPU和NPU的多种算力设备; - 💾 大量可重用的基线数据 (rllte-hub); - 👨✈️ 基于大语言模型打造的Copilot。
项目结构如下:

有关这些模块的详细描述,请参阅API文档。
快速入门
安装
- 前置条件
当前,我们建议使用Python>=3.8,用户可以通过以下方式创建虚拟环境:
- 通过
pip
打开终端通过pip安装 rllte:
- 通过
git
开启终端从[GitHub]中复制仓库(https://github.com/RLE-Foundation/rllte):
在这之后, 运行以下命令行安装所需的包:更详细的安装说明, 请参阅, 入门指南.
快速训练内置算法
RLLTE为广受认可的强化学习算法提供了高质量的实现,并且设计了简单友好的界面用于应用构建。
使用NVIDIA GPU
假如我们要用 DrQ-v2算法解决 DeepMind Control Suite任务, 只需编写如下 train.py文件:
# import `env` and `agent` module
from rllte.env import make_dmc_env
from rllte.agent import DrQv2
if __name__ == "__main__":
device = "cuda:0"
# 创建 env, `eval_env` 可选
env = make_dmc_env(env_id="cartpole_balance", device=device)
eval_env = make_dmc_env(env_id="cartpole_balance", device=device)
# 创建 agent
agent = DrQv2(env=env, eval_env=eval_env, device=device, tag="drqv2_dmc_pixel")
# 开始训练
agent.train(num_train_steps=500000, log_interval=1000)
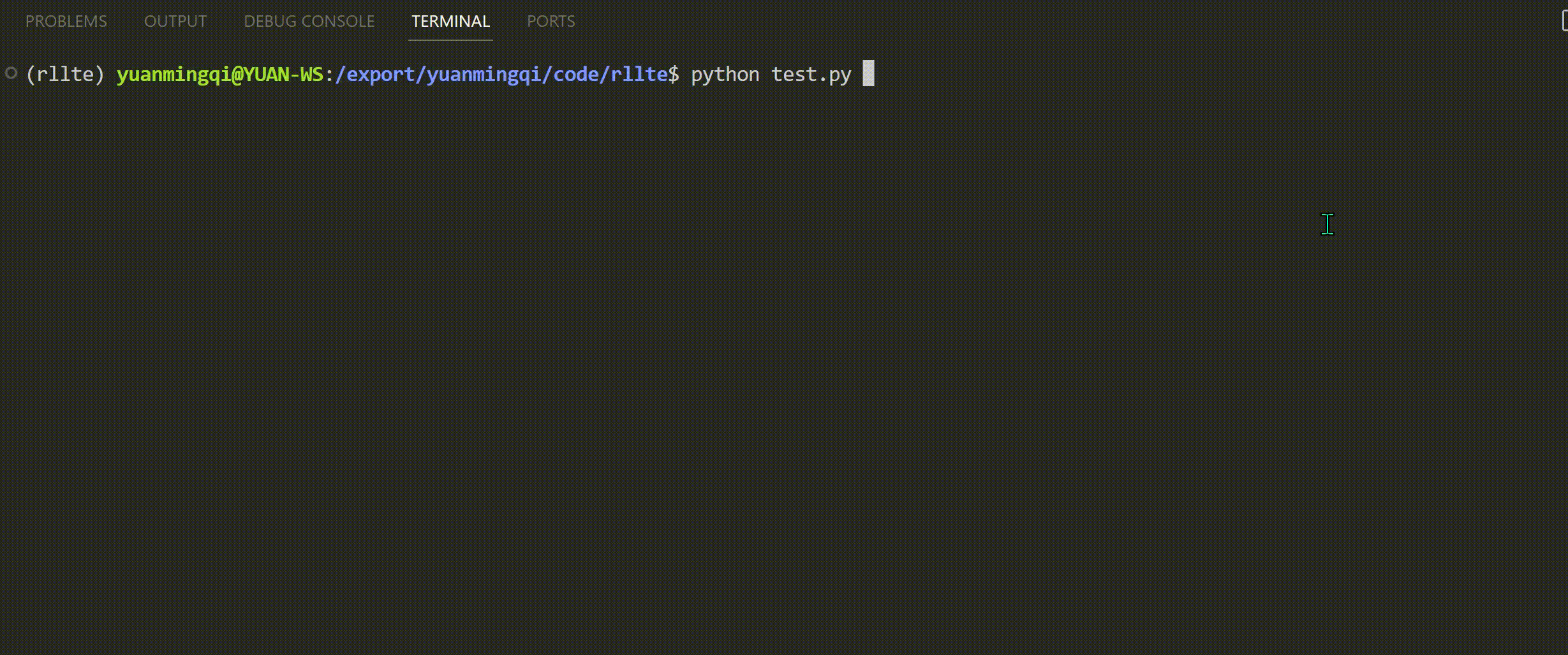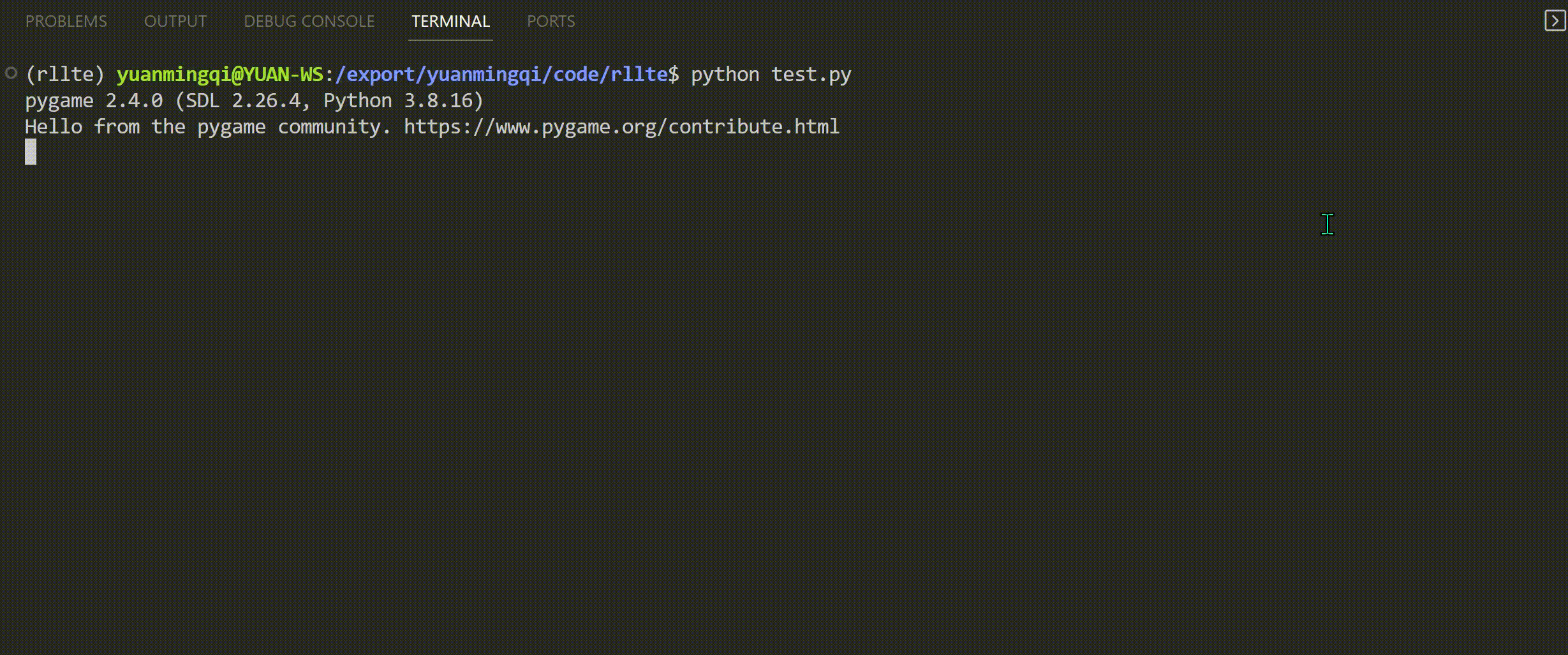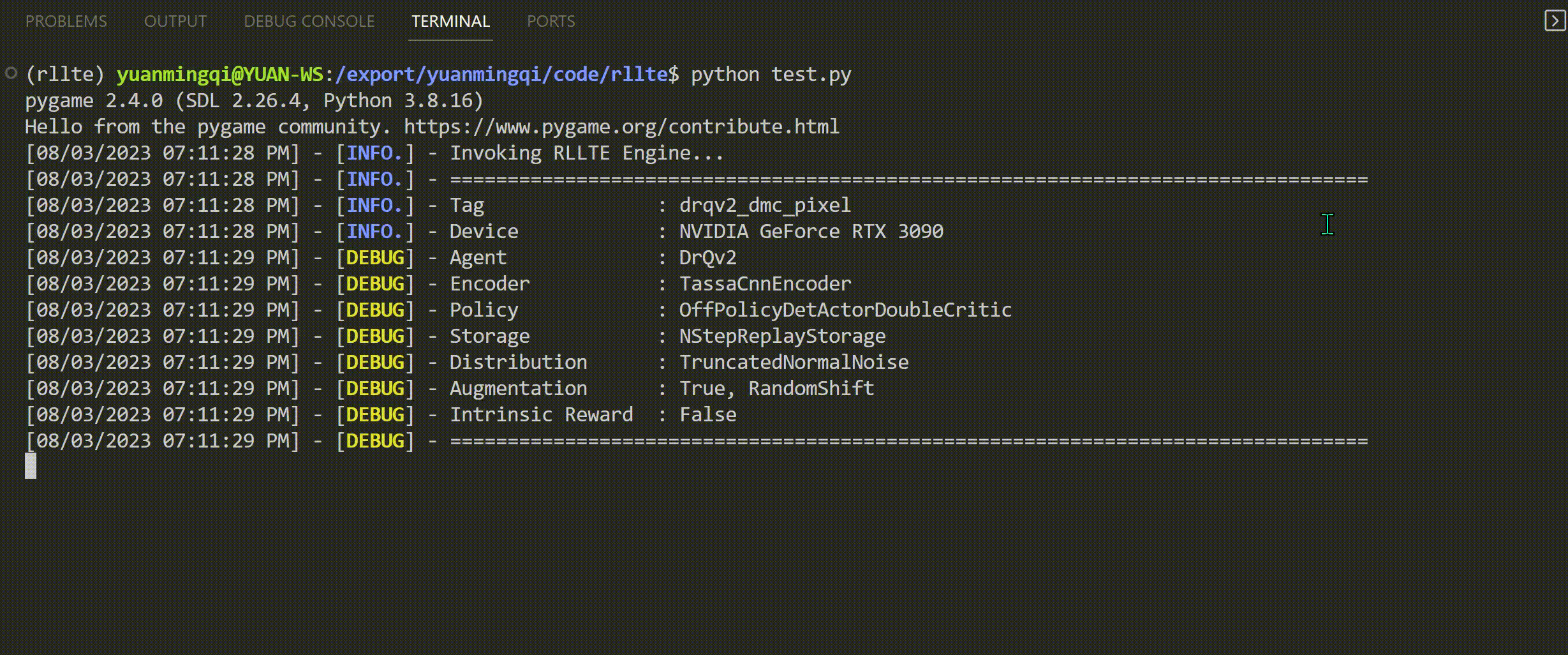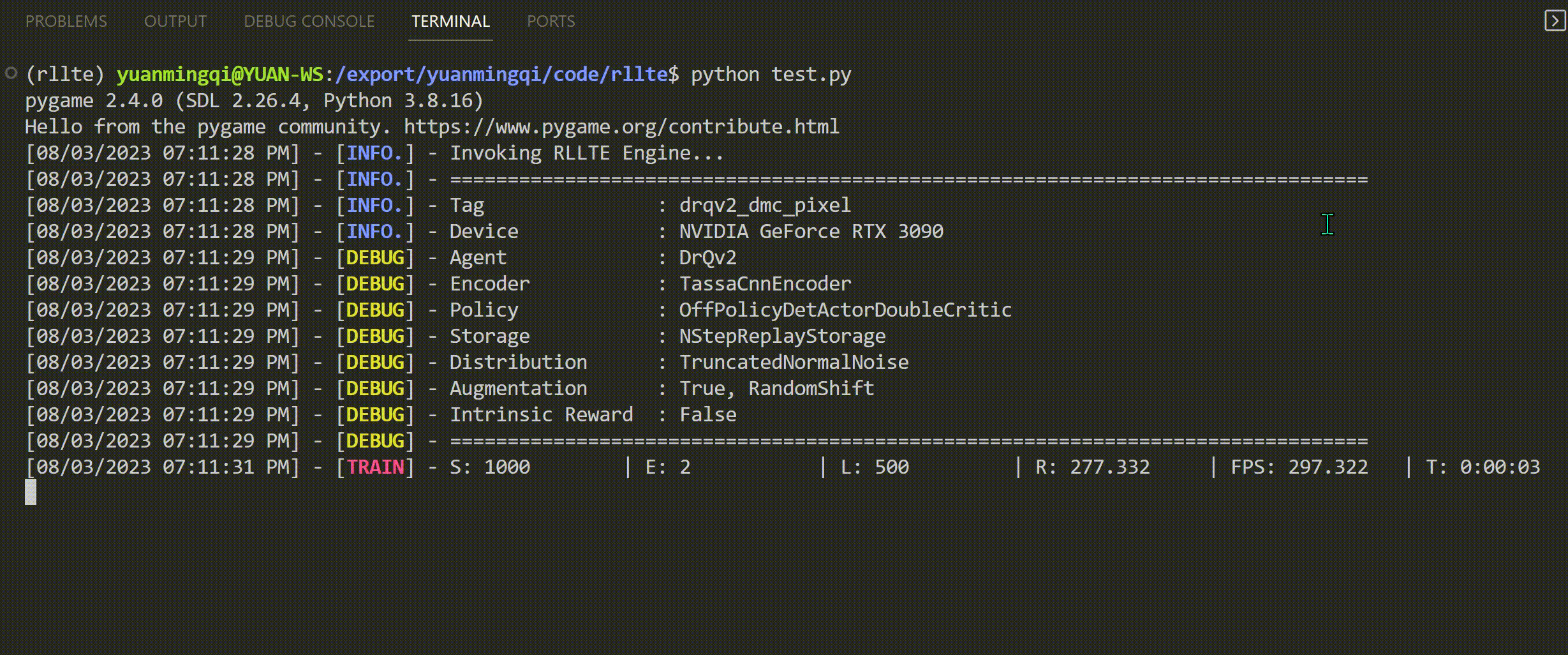
train.py文件,将会得到如下输出:
使用HUAWEI NPU
与上述案例类似, 如果需要在 HUAWEI NPU 上训练智能体,只需将 cuda 替换为 npu:
三步创建您的强化学习智能体
借助RLLTE,开发者只需三步就可以实现一个强化学习算法。接下来这个例子将展示如何实现 Advantage Actor-Critic (A2C) 算法用于解决 Atari 游戏: - 首先,调用算法原型:
- 其次,导入必要的模块:from rllte.xploit.encoder import MnihCnnEncoder
from rllte.xploit.policy import OnPolicySharedActorCritic
from rllte.xploit.storage import VanillaRolloutStorage
from rllte.xplore.distribution import Categorical
.describe 函数,运行结果如下:
OnPolicySharedActorCritic.describe()
# Output:
# ================================================================================
# Name : OnPolicySharedActorCritic
# Structure : self.encoder (shared by actor and critic), self.actor, self.critic
# Forward : obs -> self.encoder -> self.actor -> actions
# : obs -> self.encoder -> self.critic -> values
# : actions -> log_probs
# Optimizers : self.optimizers['opt'] -> (self.encoder, self.actor, self.critic)
# ================================================================================
.update 函数:
from torch import nn
import torch as th
class A2C(OnPolicyAgent):
def __init__(self, env, tag, seed, device, num_steps) -> None:
super().__init__(env=env, tag=tag, seed=seed, device=device, num_steps=num_steps)
# 创建模块
encoder = MnihCnnEncoder(observation_space=env.observation_space, feature_dim=512)
policy = OnPolicySharedActorCritic(observation_space=env.observation_space,
action_space=env.action_space,
feature_dim=512,
opt_class=th.optim.Adam,
opt_kwargs=dict(lr=2.5e-4, eps=1e-5),
init_fn="xavier_uniform"
)
storage = VanillaRolloutStorage(observation_space=env.observation_space,
action_space=env.action_space,
device=device,
storage_size=self.num_steps,
num_envs=self.num_envs,
batch_size=256
)
# 设定所有模块
self.set(encoder=encoder, policy=policy, storage=storage, distribution=Categorical)
def update(self):
for _ in range(4):
for batch in self.storage.sample():
# 评估采样的动作
new_values, new_log_probs, entropy = self.policy.evaluate_actions(obs=batch.observations, actions=batch.actions)
# 策略损失
policy_loss = - (batch.adv_targ * new_log_probs).mean()
# 价值损失
value_loss = 0.5 * (new_values.flatten() - batch.returns).pow(2).mean()
# 更新
self.policy.optimizers['opt'].zero_grad(set_to_none=True)
(value_loss * 0.5 + policy_loss - entropy * 0.01).backward()
nn.utils.clip_grad_norm_(self.policy.parameters(), 0.5)
self.policy.optimizers['opt'].step()
from rllte.env import make_atari_env
if __name__ == "__main__":
device = "cuda"
env = make_atari_env("PongNoFrameskip-v4", num_envs=8, seed=0, device=device)
agent = A2C(env=env, tag="a2c_atari", seed=0, device=device, num_steps=128)
agent.train(num_train_steps=10000000)
算法解耦与模块替代
RLLTE 许可开发者将预设好的模块替换,以便于进行算法性能比较和优化。开发者可以将预设模块替换成别的类型的内置模块或者自定义模块。假设我们想要对比不同编码器的效果,只需要调用其中 .set 函数:
from rllte.xploit.encoder import EspeholtResidualEncoder
encoder = EspeholtResidualEncoder(...)
agent.set(encoder=encoder)
功能列表 (部分)
强化学习智能体
| 类型 | 算法 | 连续 | 离散 | 多重二元 | 多重离散 | 多进程 | NPU | 💰 | 🔭 |
|---|---|---|---|---|---|---|---|---|---|
| On-Policy | A2C | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| On-Policy | PPO | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| On-Policy | DrAC | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| On-Policy | DAAC | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| On-Policy | DrDAAC | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| On-Policy | PPG | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
| Off-Policy | DQN | ✔️ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
| Off-Policy | DDPG | ✔️ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
| Off-Policy | SAC | ✔️ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
| Off-Policy | TD3 | ✔️ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
| Off-Policy | DrQ-v2 | ✔️ | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ |
| Distributed | IMPALA | ✔️ | ✔️ | ❌ | ❌ | ✔️ | ❌ | ❌ | ❌ |
- 🐌:开发中;
- 💰:支持内在奖励塑造;
- 🔭:支持观测增强。
内在奖励模块
| 类型 | 模块 |
|---|---|
| Count-based | PseudoCounts, RND |
| Curiosity-driven | ICM, GIRM, RIDE |
| Memory-based | NGU |
| Information theory-based | RE3, RISE, REVD |
详细案例请参考 Tutorials: Use Intrinsic Reward and Observation Augmentation。
RLLTE 生态环境
探索RLLTE生态以加速您的研究:
- Hub:提供快速训练的 API 接口以及可重复使用的基准测试;
- Evaluation:提供可信赖的模型评估标准;
- Env:提供封装完善的环境;
- Deployment:提供便捷的算法部署接口;
- Pre-training:提供多种强化学习预训练的方式;
- Copilot:提供大语言模型 copilot。
API 文档
请参阅我们便捷的 API 文档:https://docs.rllte.dev/

如何贡献
欢迎参与贡献我们的项目!在您准备编程之前,请先参阅CONTRIBUTING.md。
引用项目
如果您想在研究中引用 RLLTE,请参考如下格式:
@software{rllte,
author = {Mingqi Yuan, Zequn Zhang, Yang Xu, Shihao Luo, Bo Li, Xin Jin, and Wenjun Zeng},
title = {RLLTE: Long-Term Evolution Project of Reinforcement Learning},
url = {https://github.com/RLE-Foundation/rllte},
year = {2023},
}
致谢
该项目由 香港理工大学,东方理工高等研究院,以及 FLW-Foundation赞助。 东方理工高性能计算中心 提供了 GPU 计算平台, 华为异腾 提供了 NPU 计算平台。该项目的部分代码参考了其他优秀的开源项目,请参见 ACKNOWLEDGMENT.md。